AI is moving fast, and if you’re building anything serious with large language models right now, you’ve probably hit a wall: text-only retrieval just isn’t enough anymore. That’s where multimodal RAG for images and text comes in. By pairing retrieval-augmented generation with a robust vector database for RAG, businesses can give their AI real, contextual memory across documents, visuals, charts, and code. From AWS vector database setups to LlamaIndex pipelines, this blog walks you through everything that matters right now in 2026.
Ready to build AI-powered products that actually work at scale? Connect with Us Today
Before we get into the specifics, let’s ground this in something real. Most LLMs, even the brilliant ones, are stateless. They don’t remember your data unless you feed it to them every single time. RAG fixes that. But classic RAG only works with text. So when your data includes product images, scanned PDFs, charts, or video thumbnails, you need something far more capable. That something is multimodal RAG. And it relies almost entirely on how well your vector database performs underneath it all.
What Is a Vector Database in AI and Why Does It Power Modern RAG Systems?
If you’re still fuzzy on ‘what is a vector database in AI?’, you’re not alone. Most people assume it’s just another type of database. It’s actually quite different, and understanding that difference is the key to understanding why RAG works at all. Globally, the vector database market was valued at USD 2.65 billion in 2025 and is projected to reach USD 8.94 billion by 2030, growing at a CAGR of 27.5%. That’s not hype. That’s infrastructure becoming mandatory.
Understanding Vector Embeddings and Semantic Search

A vector database is a database that represents data as high-dimensional numerical vectors called embeddings. These embeddings represent meaning and context, not just keywords. Thus, when a user searches for “affordable cars,” the search engine will return results related to budget cars, second-hand cars, and fuel-efficient cars, even if these keywords are not used, since they are not present in the search query. This is semantic search, and this is the foundation of every modern RAG pipeline.
- Embeddings encode meaning: Text, images, and audio are all converted into numerical vectors that capture their semantic content, not just surface-level keywords.
- Similarity search at scale: Vector DBs employ HNSW or IVF search algorithms to find nearest neighbors in milliseconds, even for billions of vectors.
- Cross-modal retrieval: A single query can return a relevant paragraph and a relevant image because they share the same vector space.
- Real-time indexing: Unlike traditional databases, vector DBs handle live data ingestion without major performance degradation, which matters at a production scale.
Popular Vector Databases Used in RAG Pipelines in 2026
Choosing the correct vector storage solution is what will make or break your RAG system. The choices are not created equal, and there are very real trade-offs based on your size, budget, and infrastructure preferences. As of 2026, the most widely supported and mature solutions include Pinecone, Qdrant, Weaviate, Chroma, and pgvector.
- Pinecone: Fully managed, developer-friendly, and great for fast starts. Best for teams who want zero infrastructure management.
- Weaviate: Open-source with hybrid search (vector + keyword). Excellent for enterprise workloads with strict metadata requirements.
- Qdrant: Rust-based and extremely fast. Strong payload filtering. Growing rapidly, especially in cost-conscious production setups.
- Chroma: Local-first and extremely lightweight. Ideal for prototyping multimodal RAG LlamaIndex applications before migrating to managed infrastructure.
- pgvector: A PostgreSQL extension for vector search. Extremely useful if you are already running an SQL infrastructure and do not want to introduce another layer of infrastructure.
Pro Tip: Choose Based On Data Modality, Not Just Speed
Speed matters, but your vector store choice should also factor in the kind of data you’re embedding. Image vectors are significantly larger than text vectors, so storage costs and query latency behave differently at scale. Always benchmark with your actual data before committing to a vendor.
REFERENCES
- What is a Vector Database? (Pinecone Official)
- Vector Database Market Report 2025 (MarketsandMarkets)
See How We Build AI-Powered Platforms
Now that the foundation is clear, let’s talk about what makes multimodal RAG genuinely different from what most teams are currently running. Because the leap from text-only to multimodal isn’t just a technical upgrade. It changes what questions your AI can actually answer.
Multimodal RAG for Images and Text: How It Actually Works Under the Hood
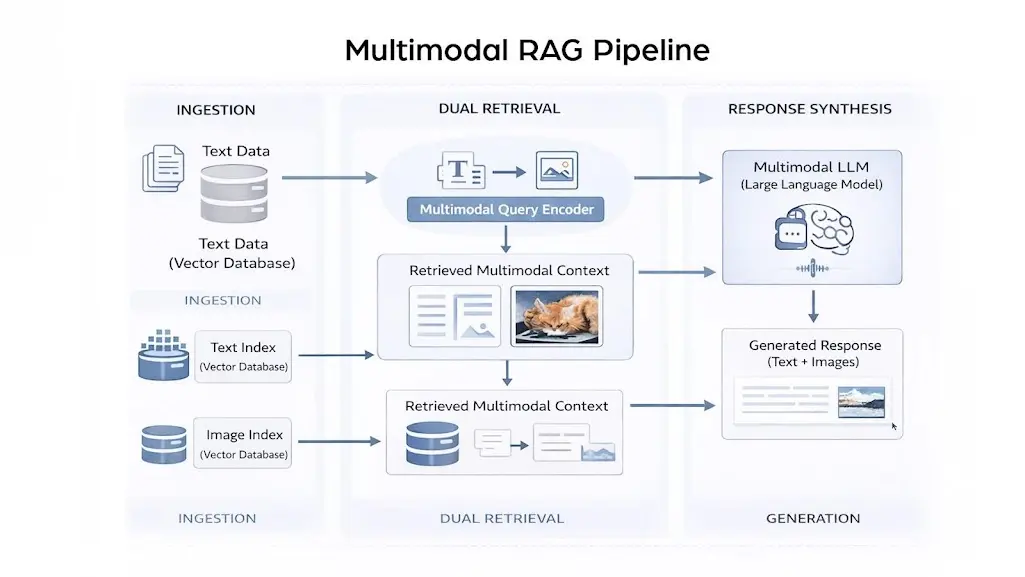
Multimodal RAG for images and text extends the classic retrieve-then-generate loop by handling more than one type of data at retrieval time. Instead of pulling only text chunks, your system retrieves a relevant diagram, scanned invoice, or labeled product photo, then passes everything to a multimodal LLM for a coherent response. The result is genuinely smarter output. The global RAG market was valued at USD 2.33 billion in 2025 and is expected to reach USD 3.33 billion in 2026, with a projected CAGR of 42.7% through 2035 as enterprises prioritize grounded, fact-checked AI.
REFERENCES & RELATED READING
- Multimodal RAG Survey and Open Challenges (arXiv, 2023)
- RAG Market Outlook 2035 (Next Move Strategy Consulting)
Read: How Mobile App Development Will Grow Your Business in 2026
The Three Retrieval Strategies in Multimodal RAG
Not all multimodal RAG setups are built the same. Researchers and engineers have settled on three main architectural patterns, each with its own trade-offs. Knowing which to pick saves a significant amount of rework later.
- Text-only retrieval with image as context: Images are converted to text summaries or captions via CLIP or GPT-4o, which are then embedded and retrieved normally. Simpler to implement, but loses significant visual nuance.
- Multimodal modality indexing: There is a separate index for text and images. The retriever looks at both simultaneously and fuses the response before forwarding it to the LLM. More precise, but more difficult to scale.
- Shared embedding space retrieval: Both text and images are embedded using a unified model like CLIP or ImageBind into the same vector space. A single query retrieves the most semantically relevant result regardless of modality. This is the 2026 gold standard for production multimodal RAG.
Why Shared Embedding Spaces Are a Game Changer in 2026
Magic happens when text and images coexist in the same vector space. You can ask a question with text and receive an image, or you can ask with an image and receive a document. This opens up a whole new line of uses that just weren’t possible before, especially in the healthcare, legal, and e-commerce fields.
- Medical Imaging: Find matching patient scan reports by uploading a similar scan as a query.
- Legal Document Review: Re-identified complex clauses in scanned PDFs using unannotated, plain language queries.
- Product Search: Identify the most similar product catalog entry to an image from a customer based on visual similarity.
- Manufacturing QA: Cross-match a defective product photo with known defect patterns in the visual knowledge base on independent time.
Embedding Model Selection In 2026: Clip vs. Llava vs. Imagebind vs. ColPali
CLIP from OpenAI remains the most widely supported shared-space model. LLaVA adds instruction-following to visual understanding, making it better for complex Q&A tasks. ImageBind from Meta extends the space to include audio and sensor data. ColPali, an emerging 2025 architecture, operates at the page level without chunking, removing one of the most painful preprocessing steps in the multimodal RAG pipeline.
One framework is quietly becoming the go-to choice for teams building multimodal RAG in Python. If you’ve spent any time in the LLM ecosystem, you already know it. Let’s get into what makes multimodal RAG with LlamaIndex so developer-friendly and genuinely production-ready.
Multimodal RAG LlamaIndex: Building Pipelines That Actually Scale in 2026
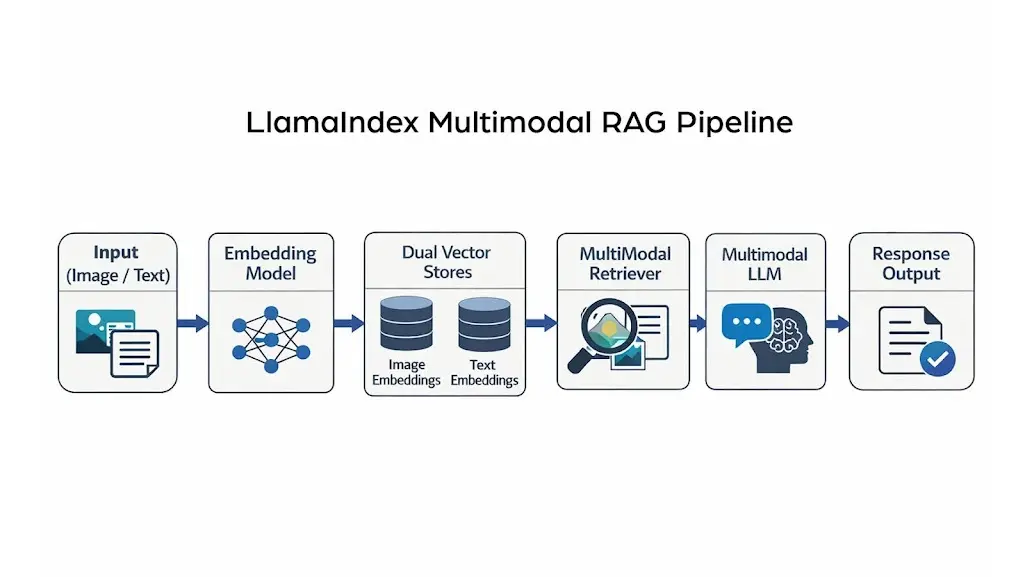
Multimodal RAG LlamaIndex is no longer experimental. The LlamaIndex framework now has first-class support for multi-vector stores, image nodes, and cross-modal query engines. Teams using it go from prototype to production significantly faster than rolling a custom pipeline from scratch. That matters a lot when speed-to-market is part of your competitive edge. According to McKinsey’s 2025 State of AI report, 71% of organizations now regularly use generative AI in at least one business function. The teams winning that race are the ones with the right tooling.
Key LlamaIndex Components for Multimodal Pipelines in 2026
LlamaIndex is modular by design. You don’t need every component, but understanding the key pieces helps you build something that won’t fall apart under real load. Here’s what the core multimodal stack looks like today.
- SimpleDirectoryReader with image capabilities: Reads mixed-content directories (PDFs, PNGs, CSVs) in a single call. Automatically processes OCR-extracted text from scanned images.
- MultiModalVectorStoreIndex: Indexes text and image vector stores separately but queries them jointly. Native support for Qdrant, Weaviate, and Chroma.
- MultiModalRetrieval: Search on the text store and image store at the same time, also supports adjusting the similarity threshold for each modality. Essential for precision control.
- MultiModalResponseSynthesizer: Generating a final response involving textual and imagery nodes using a multimodal language model like GPT-40 or LLaVA-1. 6.
A Real-World LlamaIndex Multimodal RAG Use Case: E-Commerce Search in 2026
For example, let’s say we’d prefer to do so on an application for a fashion e-commerce website where users can upload a picture of an outfit they like and find similar-looking clothing. A LlamaIndex multimodal RAG pipeline is perfect for this. The image is encoded as a vector with CLIP, passed to the product image index similarity search query, and similar products are returned as natural language answers along with price and availability information.
- Step 1: User uploads an image query. No text needed.
- Step 2: CLIP is based on one vector representation of the image and looks it up in a catalog where products are stored.
- Step 3: The top 5 closest products are returned with their text description.
- Step 4: Example GPT-4o generates a natural language response including product name, price, and stock status.
- Step 5: The user gets a conversational shopping experience that feels genuinely human.
LLAMAINDEX VS. LANGCHAIN FOR MULTIMODAL RAG IN 2026: WHICH ONE TO PICK?
Both are solid frameworks. LangChain has a larger community and more third-party integrations. LlamaIndex, though, was purpose-built for retrieval-heavy applications, which gives it a structural advantage for complex RAG pipelines. For multimodal specifically, LlamaIndex’s native image node support reduces boilerplate significantly and is the preferred choice heading into 2026.
REFERENCES
- LlamaIndex Official: Multi-Modal RAG with PDF Tables
Here’s a question engineering teams ask a lot: “We’re already on AWS. Do we need a separate vector DB, or can we use something native?” Great question. The answer is nuanced, and it depends on what you’re optimizing for.
AWS Vector Database Options for RAG: What’s Available and What Works in 2026
Amazon Web Services has been moving fast to support AI workloads, and the AWS vector database landscape has changed significantly over the past 18 months. Whether you want a fully managed option or want to run open-source tooling on AWS infrastructure, there’s a solid path. Notably, Gartner predicts that by 2026, over 80% of enterprises will have used generative AI APIs or deployed GenAI-enabled applications in production. That’s a lot of teams needing scalable vector infrastructure very soon.
Breaking Down AWS’s Native Vector Search Options in 2026
AWS has several services with vector search capability. It is important to know which one will maximize performance and value for your needs.
- Amazon Aurora PostgreSQL with pgvector: The simplest way to try out vector search if you’re already on Aurora. A poor option for large-scale use, but very convenient.
- Amazon OpenSearch Service with kNN: The most developed vector search service on AWS. Supports HNSW and IVF indexes. Best suited for teams that are already invested in OpenSearch and want to leverage their existing infrastructure.
- Amazon Bedrock: RAG as a service, fully managed KBS. The service wraps the chunking, embedding, and search in the background. Ideal for teams looking to get started quickly and avoid building the infrastructure themselves.
- Amazon RDS for PostgreSQL with pgvector: Same as the last, but on RDS. Not as high-performance, so cheaper for smaller-scale uses.
- EC2 + Qdrant/Weaviate (self-hosted): Like the self-hosted options mentioned for seeding, this is even more flexible and reduces costs 3x to 5x at median scales, but that does mean your team has operational overhead to manage.
Comparing AWS Vector Solutions for Multimodal RAG Workloads
Not every AWS option is equal when it comes to multimodal RAG. The comparison table below is a quick guide for teams trying to make that decision without spending weeks on benchmarks.
| AWS Service | Vector Search Type | Multimodal Support | Managed? | Best For |
| OpenSearch Service (kNN) | HNSW / IVF | Via custom embeddings | Yes | High-scale enterprise RAG |
| Aurora PostgreSQL + pgvector | Exact + Approx. NN | Via custom embeddings | Yes | Existing SQL stack |
| Bedrock Knowledge Bases | Managed RAG pipeline | Limited (text-primary) | Fully | Fast MVP / prototyping |
| EC2 + Qdrant/Weaviate | HNSW | Full multimodal support | No (self-hosted) | Maximum flexibility |
| RDS PostgreSQL + pgvector | Exact + Approx. NN | Via custom embeddings | Yes | Small- to mid-scale apps |
COST CONSIDERATION: MANAGED VS. SELF-HOSTED ON AWS IN 2026
Bedrock Knowledge Bases and OpenSearch Service are convenient, but they carry a premium. For startups and agencies delivering website application development services or mobile app development services with AI features, self-hosting Qdrant on an EC2 instance is often significantly cheaper at mid-scale. Just factor in the operational overhead before committing.
REFERENCES & RELATED READING
- What is a Vector Database? (AWS Official Documentation)
- 2025 Cloud Database Market Review (Cloud Data Insights)
So far, we’ve covered the theory, the frameworks, and the cloud infrastructure. But here’s where it gets genuinely exciting: multimodal RAG is already solving real problems for real businesses right now in 2026.
Real-World Applications of Multimodal RAG Across Industries in 2026
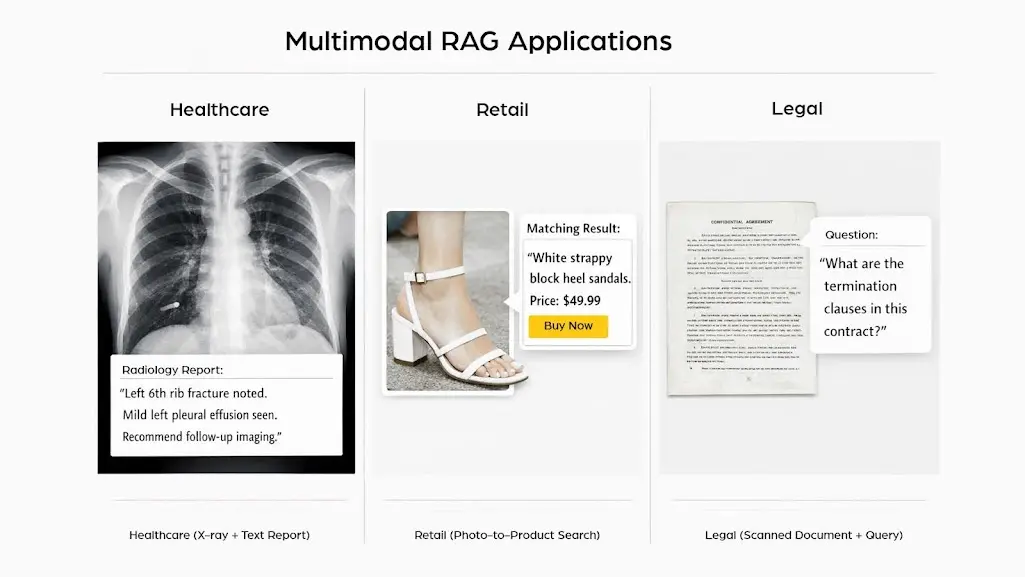
Multimodal RAG for images and text is not a future technology. Teams across healthcare, legal, retail, manufacturing, and education are deploying it in production today. And the urgency is real: a McKinsey 2025 survey found that 92% of firms plan to increase their AI budgets within the next three years. The organizations increasing those budgets are overwhelmingly doing so to move beyond text-only AI pipelines.
Industries Where Multimodal RAG Is Creating Immediate Value
These are concrete applications that are already live or in advanced pilot stages in 2026. Each one shows clearly why text-only RAG couldn’t cut it for these use cases.
- Healthcare diagnostics: A doctor interacts with a multimodal RAG system by providing it with an X-ray of a patient along with some medical notes. The system looks for similar cases in the past with images and outcomes, enabling doctors to make fast and accurate decisions.
- Document review for law firms: Document review for law firms: Law offices need to analyze thousands of scanned case records each year. In this presentation, we introduce the multimodal RAG, which allows lawyers to directly query full archives in plain English and download relevant exhibits, figures, and clauses simultaneously.
- E-commerce product discovery: Customers upload a photo of what they want. The RAG system finds the closest catalog matches and generates a conversational description with availability and pricing.
- Manufacturing quality control: Engineers query a defect database with an image of a flawed component. The system retrieves similar historical defects, root causes, and recommended fixes.
- Financial reporting: Analysts query charts and tables from quarterly earnings PDFs in natural language, getting precise data extraction without manual review.
Why Mobile App Development Companies Are Investing in Multimodal RAG Right Now
As a mobile application development agency delivering products for enterprise clients, integrating multimodal RAG into your tech stack is a serious differentiator in 2026. Users expect apps to understand context, not just process typed text. Whether it’s a field service app that photographs equipment and queries a repair manual or a retail app that matches products to customer photos, multimodal RAG makes apps genuinely smarter.
- Reduces user friction: Enables visual queries instead of typed searches, dramatically improving the experience for non-technical users.
- Improves response accuracy: Contextual retrieval across modalities produces far more relevant answers than keyword-based search.
- Enables offline semantic search: When paired with lightweight quantized models, multimodal RAG can operate offline on a device, which matters a lot for field apps.
- Creates competitive moats: AI-powered visual search features are difficult to replicate quickly, giving first-movers a meaningful head start.
MULTIMODAL RAG IN EDTECH: A GROWING OPPORTUNITY FOR 2026 AND BEYOND
Education platforms are quietly one of the biggest beneficiaries of multimodal RAG. Students photograph a math problem, a science diagram, or a textbook passage and get contextual, curriculum-aligned explanations. This is smarter tutoring at scale, and it’s already in classrooms across India and globally.
REFERENCES & RELATED READING
- Multimodal RAG: How to Build AI That Reads Images and Text Together (Towards Data Science)<
Also Read
Let’s bring this home and talk about what all of this means for businesses.
Why Businesses Should Care About Multimodal RAG Right Now
The market is shifting faster than most businesses realize. According to IDC, AI copilots will be embedded in 80% of workplace applications by 2026. That’s not a distant prediction; it’s next year. Businesses that haven’t started thinking about AI-native capabilities are already playing catch-up.
- Multimodal RAG changes what your business can actually do, not just how it looks on a pitch deck.
- If competitors are running text-only searches while you retrieve images, documents, and data together from a single query, the difference shows in customer experience, operational efficiency, and decision-making speed.
Why it matters specifically for businesses
As tools become more accessible, businesses are moving from experimentation to real implementation. The points below show what’s making multimodal RAG easier to adopt today:
- The cost of building and deploying multimodal RAG systems has dropped significantly.
- Open-source embedding models make development more accessible.
- Self-hostable vector databases like Qdrant reduce infrastructure barriers.
- Frameworks like LlamaIndex simplify building AI workflows.
- You don’t need a Silicon Valley budget to build a Silicon Valley-grade AI product.
The opportunity right now
Many businesses already have valuable data but aren’t fully using it. Multimodal RAG helps unlock this existing information for practical use:
- Indian businesses in manufacturing, retail, real estate, and healthcare sit on huge amounts of mixed-format data.
- This includes scanned documents, product photos, reports, and invoices that remain underutilized.
- Multimodal RAG turns this data into a competitive asset.
- Businesses that move on this in 2026 won’t just be early adopters; they’ll be setting the standard others need to catch up to.
THE 42WORKS PERSPECTIVE: BUILDING AI-READY APPLICATIONS FROM CHANDIGARH AND MOHALI
As a leading website development and mobile application company in Chandigarh, 42Works, we’ve been watching the multimodal RAG space closely since its early production deployments. The teams winning in the next two years are those building AI into the core of their applications, not bolting it on as a late feature. If you’re a business in Chandigarh, Mohali, or anywhere across India thinking about this, it’s a genuinely good time to start.
REFERENCES & RELATED READING
- What is Retrieval-Augmented Generation? (IBM Research)
- Hallucination Mitigation Survey via RAG (arXiv, October 2025)
Wrapping Up: Multimodal RAG Is Not a Future Thing. It’s a Right Now Thing.
We’ve covered a lot of ground. From understanding what a vector database in AI actually does, to the mechanics of multimodal RAG for images and text, to LlamaIndex pipelines, AWS vector database options, real-world use cases, and what all of this means for businesses. The throughline is simple: multimodal RAG is making LLMs dramatically more useful, and the vector database is the infrastructure that makes it possible.
If your product still relies on text-only retrieval, it’s already a step behind. If you’re building a new application and not thinking about multimodal capabilities, you’re leaving serious user value on the table. The technology is accessible, the frameworks are mature, and the use cases are proven.
Ready to build something smarter? Reach out to 42Works, and let’s talk about what multimodal RAG can do for your product.
Further Reading & External References
- Lewis et al. (2020):
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (Original RAG Paper, arXiv)
- OpenAI Research:
CLIP: Connecting Text and Images (OpenAI)
Tags
#MultimodalRAG #VectorDatabaseForRAG #AWSVectorDatabase #LLMPerformance #AIDevIndia
FAQs
1. What is multimodal RAG, and how is it different from regular RAG?
Regular RAG retrieves only text chunks to augment an LLM’s response. Multimodal RAG retrieves images, charts, and other non-text content alongside text. So instead of just pulling a relevant paragraph, your AI also pulls the relevant diagram or scanned document, making responses significantly richer and more accurate.
2. What is a vector database in AI, and do I really need one?
A vector database stores data as high-dimensional numerical embeddings and enables semantic similarity search. If you’re building any RAG system at all, yes, you need one. Traditional databases search by exact matches or keywords. Vector DBs search by meaning. That difference is what makes semantic retrieval fast and scalable.
3. Which vector database is best for RAG in production in 2026?
It depends on your scale and infrastructure. Qdrant and Weaviate are excellent for production-grade multimodal RAG. Pinecone is easier to get started with. If you’re on AWS, OpenSearch with kNN or pgvector on Aurora are solid managed options. Always benchmark with your actual data because performance varies significantly by embedding size and query volume.
4. Is multimodal RAG LlamaIndex production-ready?
Yes. As of 2025 and into 2026, LlamaIndex has stable support for multimodal pipelines, including MultiModalVectorStoreIndex and MultiModalRetriever. Teams are running it in production for visual document search and image-augmented Q&A. It’s well past the prototyping stage.
5. Does AWS have a native vector database?
AWS doesn’t have a standalone “vector database” product, but it offers vector search through Amazon OpenSearch Service (kNN), Aurora, and RDS PostgreSQL with pgvector, and fully managed RAG via Amazon Bedrock Knowledge Bases. For maximum flexibility, many teams self-host Qdrant on EC2.
6. How do you index images in a multimodal RAG system?
Images are passed through a vision-language embedding model like CLIP or LLaVA, which converts them into numerical vectors. These are stored in a vector database and queried using the same model at retrieval time. Nearest-neighbor search then finds the most semantically similar images to a text or image query.
7. What LLMs support multimodal RAG output generation in 2026?
GPT-4o, Claude 3.5 Sonnet, Google Gemini 1.5 Pro, and open-source models like LLaVA-1.6 and InternVL2 all support multimodal input. They take both retrieved text chunks and retrieved images as context and generate a unified, coherent response. Your choice depends on cost, latency, and data privacy requirements.
8. What are the main technical challenges in building multimodal RAG?
The biggest challenges are aligning text and image embeddings into a shared semantic space, managing larger vector sizes for image embeddings, handling OCR quality for scanned documents, and maintaining acceptable latency when querying multiple modality indexes simultaneously. Chunking strategy for mixed-content documents is also significantly trickier than for text-only data.
9. How does chunking work in multimodal RAG for PDF documents?
For PDFs with mixed content, text and images are extracted separately. Text is chunked into semantic units (paragraphs or sections). Images and figures are extracted and passed through a vision model to generate embeddings or captions. Both are indexed in their respective stores. Tools like LlamaParse or Unstructured.io handle this extraction pipeline efficiently.
10. Can multimodal RAG work with video content?
Yes, though it’s more complex. Video is handled by extracting keyframes at regular intervals or scene changes, then embedding each frame as an image. Audio transcripts are processed as text. Full video RAG pipelines are still more custom-built than standardized, but LlamaIndex and similar frameworks are actively adding native support.
11. What is the role of CLIP in multimodal RAG?
CLIP (Contrastive Language-Image Pre-training) creates a shared embedding space where text and images can be compared directly. In a multimodal RAG pipeline, it allows you to embed a text query and retrieve visually similar images or embed an image and retrieve relevant text passages. It’s foundational for cross-modal retrieval and remains the most widely deployed option in 2026.
12. How expensive is running a multimodal RAG system at scale?
Cost depends on the embedding model choice, the vector DB solution, and the query volume. Open-source models like CLIP reduce per-query embedding costs compared to API-based models. Self-hosting Qdrant on EC2 is significantly cheaper than managed services at mid-scale. The main cost drivers are storage for image vectors (which are larger than text vectors) and computation for embedding generation.
13. Is multimodal RAG suitable for small businesses and startups?
Absolutely. Lighter setups using Chroma plus CLIP plus LLaVA can run on a single GPU server or a powerful cloud VM. Startups building product differentiation through AI don’t need massive infrastructure to start. Validate the use case first, then scale the infrastructure as usage grows.
14. What emerging trends are shaping multimodal RAG heading into 2026?
Key trends include ColPali for page-level retrieval without chunking, native document understanding in frontier LLMs reducing preprocessing overhead, audio and sensor modalities being added via ImageBind, and on-device RAG for privacy-sensitive mobile applications. The pace of change is genuinely fast and showing no signs of slowing.
15. How can I contact 42Works to build a multimodal RAG or AI-powered application?
Really easy. You can reach the 42Works team directly at contact@42works.net or call them at +91-9517770042. We work with businesses across Chandigarh, Mohali, and all of India and have hands-on experience building AI-powered mobile applications and web application development services. Just reach out and tell us what you’re trying to build.


